













This article originates from Dominic's presentation at the virtual Customer Success Festival in 2021. Catch up on this presentation, and others, using our OnDemand service. For more exclusive content, visit your membership dashboard.
Hi there! My name is Dominic Constandi, and I'm Vice President of Customer Experience at ZoomInfo. I'm excited to share a look at how to balance stats with personal knowledge across various levels of scale.
Here we have our handy dandy agenda:
- A menu of metrics – We're going to broach this first by taking a quick tour through some of our favorite stats, metrics, and CS acronyms.
- Closing the gap – We’ll highlight how a super stats dashboard, while undeniably powerful, won't tell us everything we want to know about our customers then explore some methods for closing the gap.
- Looking upwards – We’ll talk about how we can reach a more highly evolved state of CS where qualitative data, your personal knowledge, and your prior experience can be used to make data-driven decisions.
A menu of metrics
Let’s start by taking a look at the usual suspects.
I've very loosely grouped these metrics into three broad categories: firmographic, adoption, and CSAT and health. This list is certainly not meant to be exhaustive, merely representative of some of the things that you might measure or care about, depending upon your org maturity, budget, tech stack, resource allotment, etc.

On the firmographic side, we've got customer attributes that typically form the foundation of our segmentation methodology and subsequent engagement model with our customers:
- Customer size – be that in the form of the raw employee count or your product’s user base
- Customer spend – while technically not a firmographic stat, it often plays a part in segmentation and engagement models, so it makes the cut
- Geography
- Vertical
Next, we've got all the stats and bountiful acronyms that make up our adoption bucket:
- Provisioned/sold
- Active/provisioned
- Monthly active users (MAU)
- Weekly active users (WAU)
- Daily active users/monthly active users (DAU/MAU) – this is especially useful for gauging customer stickiness
- Key beats – more on this in a moment
These are all things that both a CS org and a product marketing org are likely to be tracking as they give insight into your usage funnel. Those with a keen eye may have noticed that I've listed these items out to reflect the funnel concept.
Now, just a quick side note on key beats – this is a concept that we use here at ZoomInfo. It refers to specific actions and types of usage that have been linked to the most positive renewal events, based on the analysis of many sample sets.
To expand upon that, I'll step outside of my ZoomInfo paradigm just for a moment and use an example we can all relate to – one that involves our mobile phones, in this case, my iPhone. Some fairly standard use cases for the iPhone include calls, text messages, and alarms. In this example, I'm going to focus on the alarm feature.

Now, I use the alarm to wake me up at a certain time every morning. It's certainly a key use case, but if we're honest, I can execute that same use case with my Motorola Razr flip phone, from circa 2001.
If I were Apple, and this was a B2B example, would I really want to gauge Dominic's loyalty to my brand by how extensive his use of the alarm feature is? Probably not. What I would want to see is if Dominic is using the phone to not only manage what time he wakes up in the morning but to manage his whole sleep routine and the way he approaches his rest time.
I’d want him to be using my new sleep schedule feature that tells him when to start winding down his screen time before bed. I'd want him to be using the sleep tracking feature and that shortcut functionality that automatically sets his alarm based on the day of the week.
Ultimately, it's these patterns of usage that are going to drive me to buy the new phone or the watch or the Airpods or the Mac or the iPad. That expansion is really going to impact my retention, my user fanaticism, and ultimately my relationship with the brand.
Plus, if I’m doing all these things, I’m probably not going to stop using Apple because that would mean ripping out the way I manage my whole sleep routine, so at that point, I’m super sticky. That’s what the concept of key beats is all about.

Now, let’s move on to the last category in our menu of metrics, which is CSAT and health. These metrics tend to come in various flavors and often allow you to kind of incorporate kind of qualitative information and assessment. Here are some of the things you’ll probably want to track:
- Net promoter score (NPS
- Engagement surveys
- Revenue at risk
- Health scoring
- Firmographic
- Usage-based
- Anecdotal
I've seen health scoring take many forms, often weighing things such as firmographic data differently.
For instance, when I look at all the customers whose contracts are set to expire in the next quarter, I'll divvy them up into different firmographic cohorts by size, industry, and geography. I'll also divvy up those cohorts based on characteristics such as if it's a first renewal or if they've been partnering with us for two-plus years.
Based on the analysis of historical data regarding renewal and churn where these characteristics are in play, I'm able to create a firmographic health score, which serves as a decent baseline for pretty broad cuts of health scoring. In short, firmographic health scoring is an immensely powerful thing for us.
The usage-based piece is where you're looking back at adoption metrics and key beats data. That's going to give you a sense of whether the customer is seeing the value that you want them to see.

Finally, there's the oh-so-important and super-valuable anecdotal health scoring. This is stuff like if budgetary constraints are coming, if there’s a new financial decision-maker in the mix, or if the business is changing strategies. These can all have a significant impact on your relationship with the customer.
With all of that said, you could have all these data points, but there will undoubtedly be gaps. Things like upcoming budget pressure aren't going to show up on a dashboard. Or you can flip it around, and say, “I've got a great relationship with the main point of contact,” but maybe that point of contact isn't seeing the ROI that they had forecasted due to anemic adoption, so you have a different sort of contradiction between your anecdotal health scoring and reality.
Closing the gaps
So how do we go about closing some of those gaps and reducing our exposure to churn that may well be actionable and unexpected?
For ZoomInfo, closing that gap means finding ways to activate personal knowledge, because while often insightful, it's almost impossible to build repeatable, scalable, and measurable motions based on data that resides in non-normalized, non-transparent, non-centralized mediums.
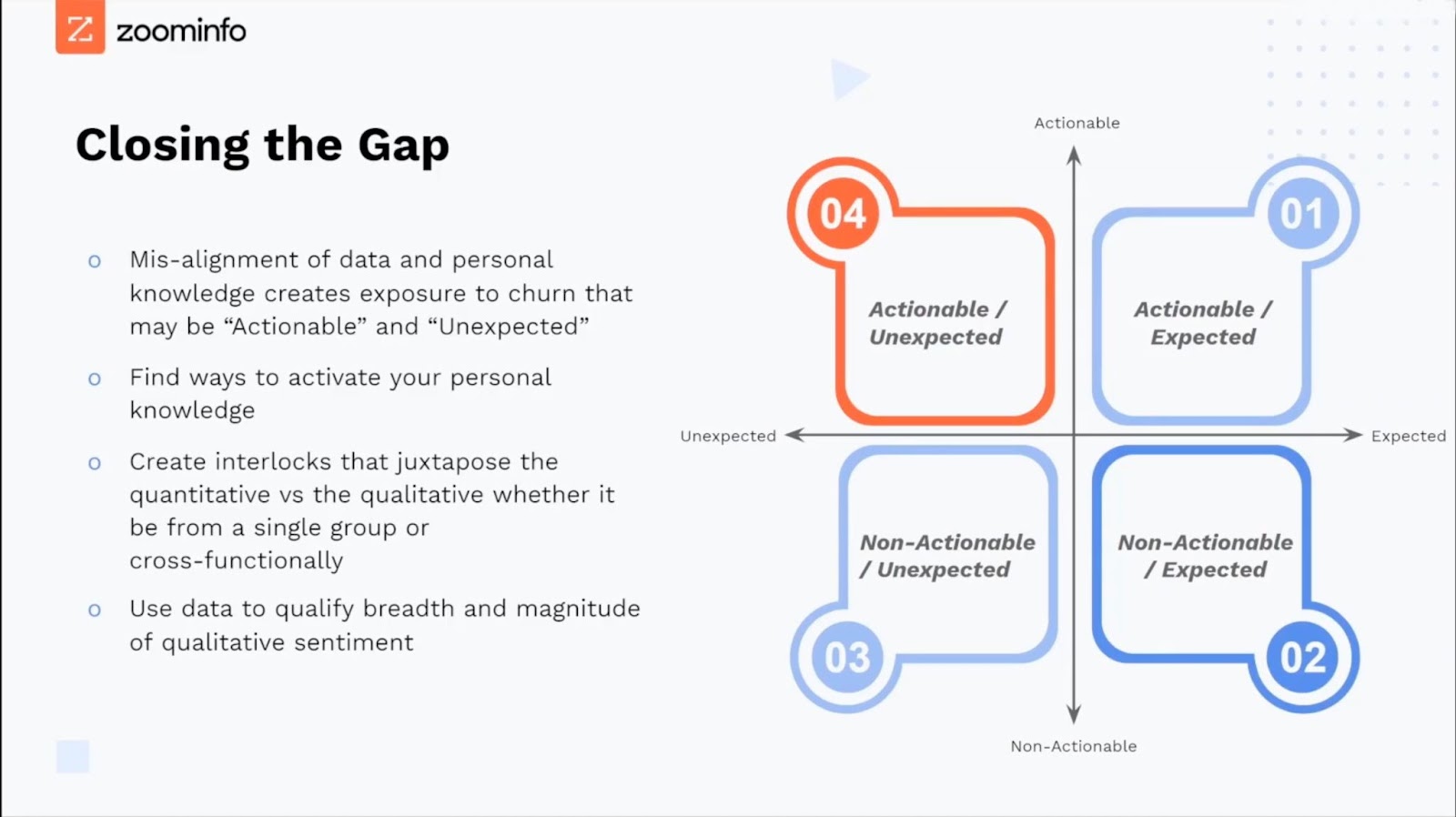
To reiterate, activating your personal knowledge is key. To illustrate this, I’ll share a few motions that ZoomInfo has run. They’re by no means revolutionary, but I’ve found them to be effective nonetheless.
First up, we’ll look at how we flag at-risk accounts.
In the 30, 60, and 90 days leading up to renewal, the account management team and the CS team check the risk statuses across their shared books of business. We look at firmographic health scoring and usage-based health scoring, and the Customer Success Manager (CSM) will flag if there’s a downgrade risk, a churn risk, or no risk at all.
If there is a risk of downgrade or a risk of churn, we normalize those flags by creating a standardized dropdown so that we can determine the root causes and sub-root causes of that risk. Now, the question is whether that data aligns with anecdotal knowledge within the CS team or across other parts of the business.
In this example, there’s another stakeholder in the renewal event: the account manager (AM). They are most likely managing the renewal within their business using an opportunity stage or something akin to that.
A simple motion that we run is to cross-reference what all of our sources are telling us about each account. Usually, the exercise uncovers some really interesting gaps and misalignments.

For instance, the AM might say that a renewal is likely because they’ve had a positive discourse with the main point of contact. However, outside of that, the usage metrics might be pretty anemic across large swaths of the user base, which ultimately might end up blowing up in our faces if the buyer pulls a usage report prior to approving the renewal. That's why we've created an interlock that's going to juxtapose the quantitative and the qualitative and bring any gaps to light.
Let’s look at another example.
A whole cohort of your company is customer-facing – you’ve got your CSMs, account execs, and so on – and you as a business want to get a sense of how people are reacting to your most recent price increase. Getting a good read on that data can be tricky because you're often getting these reactions in real time during phone calls or video calls when a host of other things are being covered.
You could certainly poll your customer-facing groups to get an anecdotal qualitative read on how the price increase has been received by the customer base. However, that qualitative sentiment becomes more powerful when you're able to qualify its magnitude with data. You’re probably aware of sales enablement tools that do just that – they help quantify the breadth and magnitude of how customers are responding to certain events or stimuli that they're facing.
Using data to qualify the breadth and magnitude of a qualitative sentiment doesn't discount the qualitative sentiment; it merely validates it and, thus, augments its significance or potentially diminishes its significance.

Looking upwards
Thus far, we've talked about the data, both qualitative and quantitative. We've talked about the importance of reconciling the gaps, and we've covered a couple of tactical motions that you can scale up or scale down, according to what's feasible for your business. Now, I'm going to try and bring this home by talking a little bit about the higher goal.
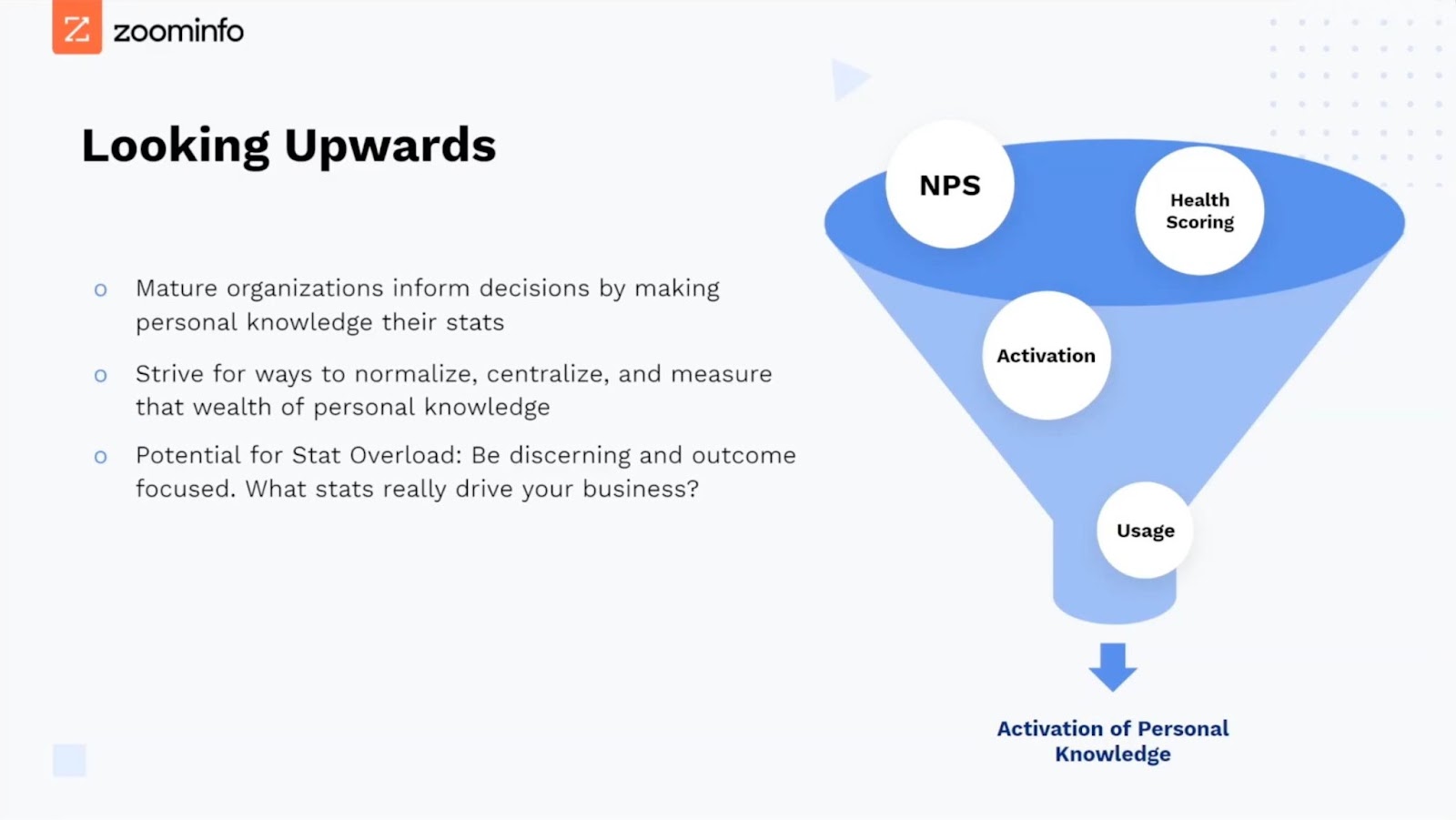
Put simply, mature organizations find ways to make personal knowledge their stats. Remember, we like stats because they can be normalized, centralized, scaled, and measured. But we want stats that are both system-derived and automated. We also want stats that are inferred and qualified by humans.
It's not personal knowledge versus statistics so much as it's the coalescence of the two because ultimately, you want to make data-driven decisions.
Strive always for ways to normalize, centralize, scale, and measure the wealth of personal knowledge that exists within your business.
Once you've taken a step forward in that direction, be discerning and outcome-focused. Track what events or metrics correlate to upsell or renewal. You want to avoid the potential for stat overload. There are a lot of things you can measure, and sometimes you find yourself with all these stats for stats' sake, which is the opposite of outcome-driven.
I'll close with a final example that hopefully adds some level of ridiculousness and humor. Let's say I'm a CSM and I'm talking to a handful of my customers and hearing how if our products could just help them iron their trousers or somesuch, they'd be much more likely to renew and expand our partnership.
Now, this isn't a bug. There's no Jira ticket on it because our product's primary use case is not to help people iron their trousers. All this talk of ironing is just knowledge that lives in my head. For all I know, there might also be customers across other parts of the business that I'm not talking to who are churning because they too have that same feedback. Meanwhile, my personal knowledge about this gripe is just laying dormant. It's not activated, so we want to activate it.
That personal knowledge becomes activated if I can go to a centralized system and create a feature request that says, in a normalized way, “topic = trousers, enhancement = aiding with the ironing of the trousers, special edge case or consideration = trousers with pleats.”

I've got that normalized data now, and other CSMs can see it and they can add their own normalized customer data to that list. From there, the business can estimate the total average customer value that might be impacted by that cohort of customers. The product team can estimate the opportunity cost of building that enhancement request. All of a sudden, this personal knowledge becomes quantifiable and measurable.
This is just a silly example, but hopefully, it drives the point home that you can activate your personal knowledge by making it your stats. That’s going to make your case so much more compelling when you go to your product team with a request.
That is all from me for now. Thank you so much for reading.
If you enjoyed Dominic's article, why not have look at our customer success event calendar, and witness CS brilliance like this first-hand? 👇



Become a CSC Insider
Thank you for subscribing
Get exclusive insights, frameworks, and strategies from customer success leaders driving real business impact.
An email has been successfully sent to confirm your subscription.
 Follow us on LinkedIn
Follow us on LinkedIn



